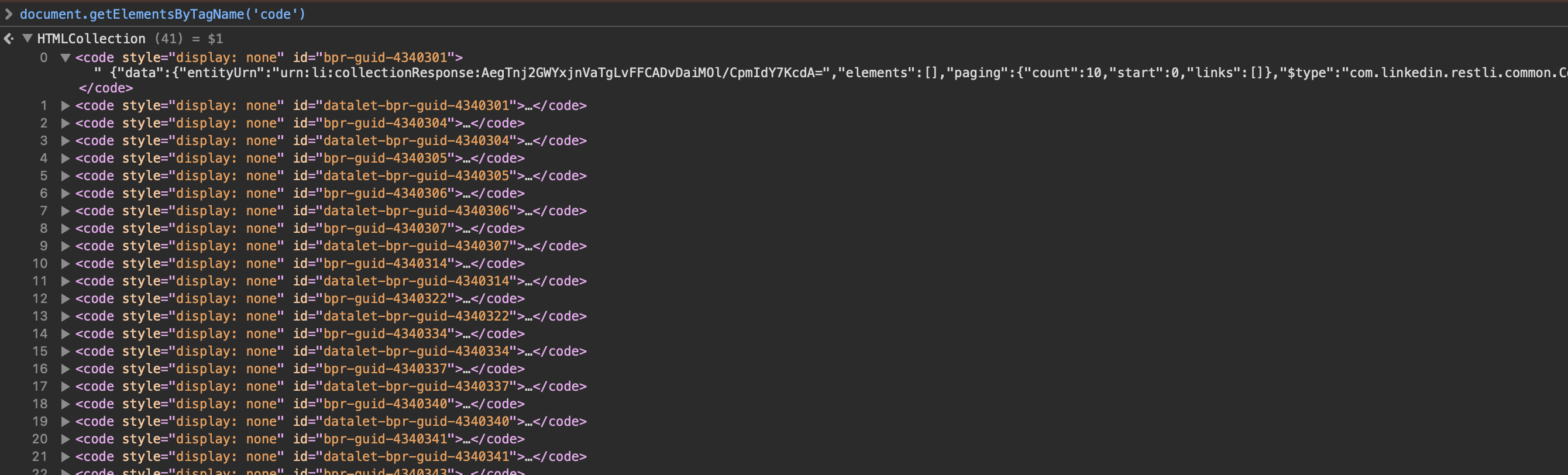
Pour linkedin, code se retrouve être une balise cachée dans laquelle ils embarquent des données.
Mon content script évitait déjà les balises script et autres styles mais de la à penser que le contenu des balises code doivent être ignorés, il faut vraiment avoir l’esprit tordu.
Faites une requête avec le mot « emprise » dans un moteur de recherche type google. Vous obtenez des résultats. C’est sur le web et dans un browser. Mon test pour dire que c’est du web est que c’est modifiable/remixable: par exemple:
Cela retourne des résultats avec lesquels ont peut jouer (console JS/DOM, user scripts, ..etc)
Par contre, si je vais sur docs.google.com, que je crée un document dans lequel je tape juste le mot « emprise », même en faisant attention à la case du texte, je n’obtiens rien avec le test précédent, mis à part un script de données qui contient ce même mot. En clair, il ne trouve pas de nodes textuelles contenant le mot en question. Et pour cause, l’affichage est en fait une balise canvas donc hors du DOM qui est l’essence du web/html. Autant mettre un binaire qui pointerai vers une VM. Ici le web n’est qu’un transport et le browser un simple réceptacle.
Ensuite le site en question trouve malin d’intercepter tous les événements clavier. Tout y passe sauf bien sûr ceux qui sont interceptés auparavant par le browser. Bref, on ne peux pas jouer ici. Ce n’est pas du web, désolé. Mauvais karma.
Gros bug avec firefox 96 sous Ubuntu 20.04. Enorme fuite de mémoire, swap plein, etc… Au final j’ai désactivé dans le about:config le fonction « network.http.http3.enabled » et tout est rentré dans l’ordre. Merci.
Ma seconde machine est un mac sur lequel j’utilise Safari. Lors d’un partage d’URL, je constate que lorsque je copie l’adresse d’un site avec un accent dans le chemin, il embarque
C’est un biais de ces dernières années d’afficher dans la barre d’adresse l’URL déséchapée et de copier l’URL réelle. Safari a tort ce qui pose des problèmes lors de la réutilisation de l’URL (par exemple document traitement de texte) même si Pages.app s’en accommode fort bien.
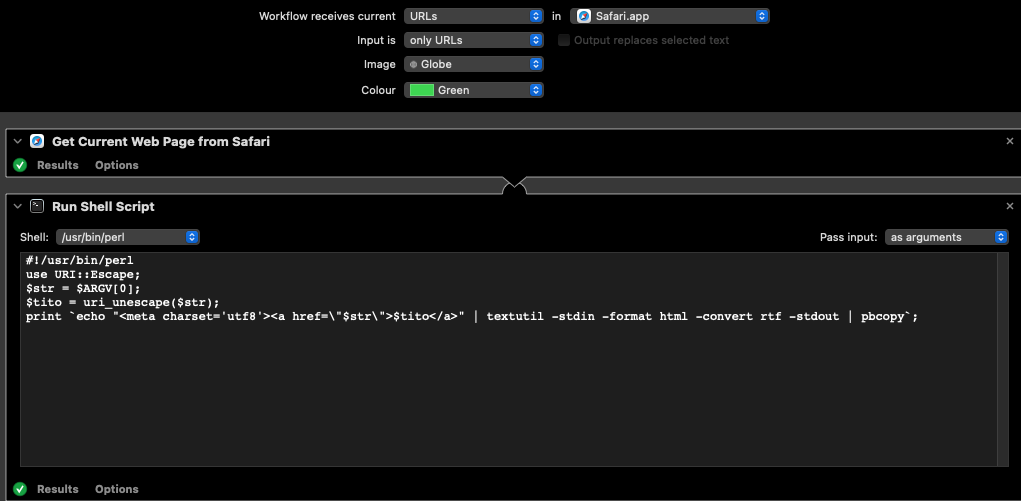
Cela me semble l’occasion de s’amuser un peu avec Automator.app avec pour objectif de mettre un lien avec l’URL bien échappée et le libellé du lien bien normalisé donc deux expressions d’une même adresse.
Je crée donc un workflow qui accepte en entrée des URLs depuis Safari.app, puis j’utilise le module « Get current web page from Safari » (qui envoie l’URL brute échappée), puis le module « Run shell Script » dans lequel je sélectionne perl et « pass input as arguments ». Reste à copie ce script:
Le gros hook dans ce script est de bien inclure le meta charset dans le bout de html passé à textutil puis pbcopy (j’ai perdu pas mal de temps avec des problèmes d’encodage).
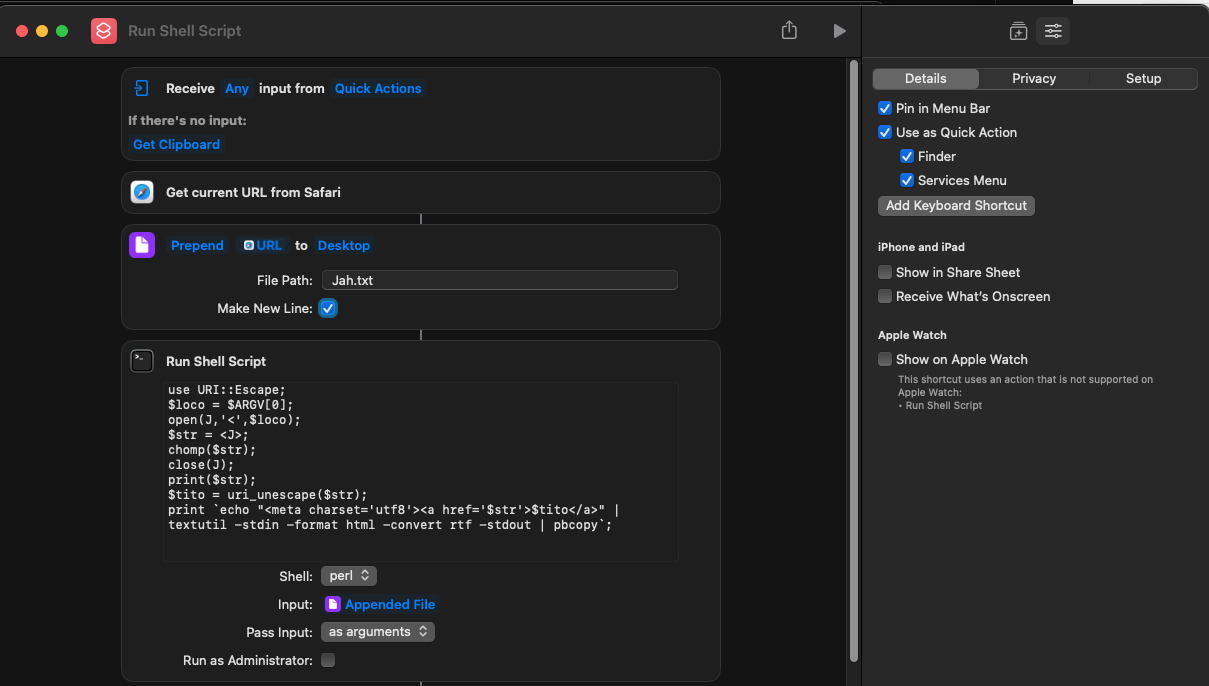
Plus qu’a créer un raccourci clavier dans les préférences d’accessibilité et le tour est joué. Cependant, sous Monterey, Automator.app est en cours de déprécation. Je passe conduire sur Shortcuts.app avec quelques hooks en raison de bugs de leur part ou d’incompréhensions de ma part. Reste que la solution suivante est fonctionnelle:
Grand fan de l’initiative letsencrypt (https://letsencrypt.org/) dont parle souvent l’EFF (https://www.eff.org/) (je suis membre), j’ai eu des problèmes avec la vérification des certificats générés par ce service sur un serveur avec une installation un peu ancienne. curl et LWP me refusaient en raison de problèmes de certificats. https://community.letsencrypt.org/t/certificate-verification-errors-when-using-curl/105335 a attiré mon attention sur le fait qu’il me manquait la ligne, à priori propre à apache 2,2 suivante, à adapter au bon domaine, dans ma config apache: SSLCertificateChainFile /etc/letsencrypt/live/privatestash.org/chain.pem
Une fois en place, plus besoin de bypass de la vérification des certificats dans LWP (use IO::Socket::SSL; $ua->ssl_opts( SSL_verify_mode => IO::Socket::SSL::SSL_VERIFY_NONE, verify_hostname =>0);) et plus besoin des mêmes options dans curl (-k), ce qui est bien plus satisfaisant.
Le truc bizarre est que les browsers ne pâtissaient pas de ce point.
Je crois que j’en ai eu assez d’entendre des politiques et autres commentateurs dire que le code du travail trop gros et que sa modification est urgente. Au delà des arguments politiques, j’aimerais mettre quelques chiffres ici, suite à mon expérience sur ces données (http://codes.droit.org) et bientôt une application iOS et des web-services.
Si je regarde le poids des PDFs que je génère pour chaque codes (droit positif + articles liés), je constate que les plus lourds sont :
sante_publique.pdf (35412646)
rural_peche_maritime.pdf (30630860)
securite_sociale.pdf (30238979)
travail.pdf (28924689)
impots.pdf (23586049)
En nombre d’articles, c’est différent:
sante_publique (11845)
travail (1123)
rural_peche_maritime (9413)
securite_sociale (7538)
commerce (6679)
Enfin, si on se contente d’observer le nombre de liens, on obtient:
sante_publique 19001
securite_sociale 17364
rural_peche_maritime 14501
travail 13442
monetaire_financier 11899
Bref, le code du travail n’est ni le plus lourd, ni le plus long.